A CSV-importok gyakrabban buknak el unalmas okokból, mint drámaiakból. A fájl rendben néz ki egy táblázatkezelőben, feltöltik egy CRM-be, CMS-be vagy belső adminfelületre, majd azért hibázik, mert a szeparátor nem az, amit a fogadó rendszer várt. A bosszantó rész az, hogy a sorok első ránézésre továbbra is teljesen ésszerűnek tűnhetnek. A gond csak akkor látszik, amikor a parser máshogy olvassa a fájlt, mint az ember, aki megnyitotta.
Az elválasztóval kapcsolatos hiba jól mutatja, miért nem elég a nyers fájl szemrevételezése. Ha sima szövegként nézed a vesszőket, pontosvesszőket, tabokat vagy pipe karaktereket, kapsz némi információt. Ha azt látod, hogyan értelmezi őket egy parser, sokkal többet kapsz.
Erre való a Converty CSV-validátora. Nem próbál adatbázis-import rendszerré válni. Abban segít, hogy még azelőtt ellenőrizd az elválasztó felismerését, a fejlécfeltételezéseket, a sorformát és a parse-olt kimenetet, mielőtt a fájl eljutna ahhoz a törékeny lépéshez, ahol egy másik rendszer visszautasítja.
Miért ilyen gyakoriak az elválasztóhibák?
Sok CSV-fájl csak laza értelemben "CSV": elválasztott szöveg, amelyet táblázatszerű cserére szántak. A tényleges szeparátor lehet vessző, pontosvessző, tab vagy pipe attól függően, milyen exportforrás, locale vagy csapatszokás hozta létre.
Ezért jelennek meg gyakran az elválasztóproblémák nemzetközi vagy több eszközt érintő workflowkban. Az egyik export alapértelmezésben pontosvesszőt használ. Egy másik tabot, mert az adatok szabad szöveges mezőiben már vannak vesszők. Egy harmadik rendszer CSV-t mond, de csendben szűk, konzisztensen idézett és fejléces struktúrát vár. Mire a fájl eljut a célrendszerbe, mindenki azt feltételezi, hogy valaki más már ellenőrizte.
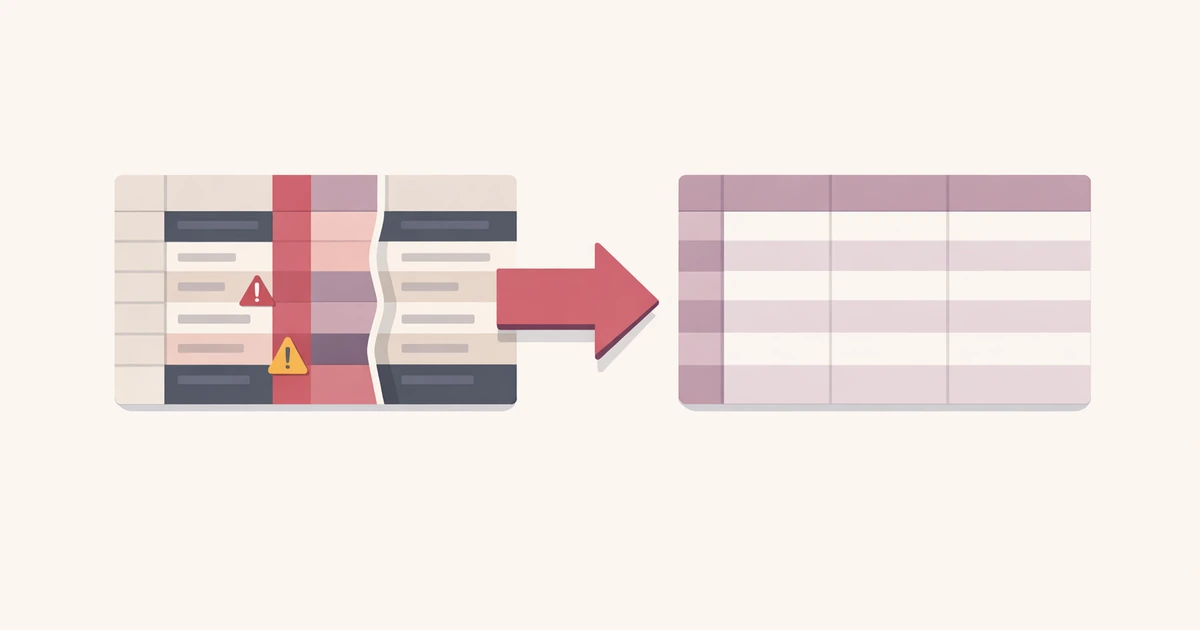
Az eredmény ismerős: a fejlécsor egyetlen oszloppá esik össze, a mezőszám a fájl közepén elcsúszik, vagy az import látszólag lefut, miközben rossz oszlopokba tolja az adatot.
Ne azt kérdezd, milyen szeparátort látsz, hanem azt, hogyan olvassa a fájlt a parser
Itt számít igazán a Converty parse-olt előnézete. Ha a parser vesszőt talál, de a fájl valójában pontosvesszőt akart, a forma azonnal szétesik. Ha pontosvesszőt talál, és a sorok szépen igazodnak, sokkal valószínűbb, hogy az import is jól viselkedik később.
Ez egyszerűnek hangzik, de megváltoztatja az ellenőrzési szokást. A nyers karakterlánc feletti vita helyett a strukturált értelmezést validálod. Az elválasztó többé nem írásjel, hanem parsing szabály, amelyet bizonyítékkal lehet megerősíteni vagy megkérdőjelezni.
Ezért tartozik össze az elválasztó-felismerés és a fejléc kapcsolója is. Egy sor lehet helyes szeparátorral parse-olva, mégis rosszul viselkedhet, ha az első sort rosszul osztályozza a rendszer.
Reális import előtti workflow
Képzeld el, hogy egy csapattag kontaktokat exportál az egyik rendszerből, és egy másikba kell importálnia őket. A fájl táblázatkezelőben rendben nyílik meg, de több oszlop idézett mezőiben vesszők vannak, az exportforrás pedig helyi táblázatkezelői alapértelmezés miatt pontosvesszővel választotta el a mezőket.
A gyorsabb workflow:
- Nyisd meg a fájlt a CSV-validátorban, vagy illessz be reprezentatív mintát.
- Ellenőrizd a felismert elválasztót, ne feltételezd.
- Kapcsold át a fejléc kezelést, ha az első sor gyanúsan viselkedik.
- Olvasd el a hibákat sorforma-problémák, duplikált fejlécek vagy üres sorok után kutatva.
- Nézd meg a parse-olt előnézetet, és erősítsd meg, hogy az oszlopok úgy állnak, ahogy a célrendszer várja.
Ez a sorrend azért működik, mert kiveszi a találgatást. Nem azt próbálod szemmel eldönteni, hogy egy vessző elválasztó-e vagy idézett mezőn belüli karakter. A parse-olt eredményt ellenőrzöd, amelyre az import épülni fog.
Az elválasztóhiba gyakran fejlécproblémával jár együtt
Ha az első sor egyetlen hosszú stringgé válik a rossz szeparátor miatt, a fájl törött fejlécesnek tűnhet, miközben az igazi gond az elválasztó. Fordítva is igaz: helyes elválasztó rossz fejlécfeltételezéssel gyanússá tehet egy egyébként strukturálisan jó fájlt.
Ezért fontos a fejléc kapcsoló. Lehetővé teszi annak ellenőrzését, hogy az első sor címkékként vagy adatként kezelendő-e, anélkül hogy újra kellene építeni a fájlt. Valódi importworkflowban ez időt takarít meg, mert a kérdés operatív: mit kell a fogadó rendszernek beolvasnia?
Az idézés, a vegyes tartalom és a soronkénti hibák mutatják meg az előnézet értékét
Az elválasztóhibák megtévesztőbbek, ha a fájl idézett szöveget, beágyazott írásjeleket vagy egyenetlen sorokat tartalmaz. Egy support export jegyzeteiben lehetnek vesszők. Egy termékkatalógus leírásaiban lehetnek pontosvesszők. Egy kézzel szerkesztett táblázatban lehet egyetlen hibás sor egy egyébként tiszta fájl közepén.
Ilyenkor a hibajegyzéket és a parse-olt előnézetet együtt kell olvasni. A figyelmeztetés megmondja, hogy valami elromlott. Az előnézet megmutatja, mit gondol a parser. Ez sokkal hasznosabb, mint egyetlen hibaüzenet, mert megmutatja, hogy az elválasztó választása törte-e el minden sort, vagy egy konkrét sor okozta a sérülést.
Ezért továbbra is hasznos a szélesebb CSV-fájlok validálása sikertelen importálás előtt útmutató. Ez a cikk szándékosan szűkebb: az elválasztófeltételezésekből eredő hibákról szól.
Javítsd a fájlt, mielőtt az importeszköz lesz a debugger
Az import rendszerek rossz helyek CSV-struktúra debugolására. Elmondják, hogy egy sor hibázott vagy elcsúszott az oszlopszám, de gyakran nem mutatják meg a fájlt úgy, hogy gyorsan javítható legyen. Ekkor már a workflow törékeny részében vagy.
Ezért értékes az import előtti validálási passz. A hibakeresést közel tartod a forrásfájlhoz, nem kényszeríted a célrendszert arra, hogy visszamagyarázza neked a fájlt. Ha a következő feladatod táblázatos adatból konfigurációs formátumokba lép át, párosítsd ezt a Miért nem érhető el a TOML-kimenet egyes JSON vagy YAML bemeneteknél cikkel. Ugyanaz a tanulság: az érvényes szöveg nem mindig jó struktúra a következő rendszernek.
Az elválasztó-ellenőrzés olcsó biztosítás
A legjobb CSV-import az, amely eseménytelennek érződik, mert a struktúrát már feltöltés előtt ellenőrizték. Az elválasztóproblémák azért bosszantóak, mert megelőzhetők. Nem kell hozzá nehéz adatplatform. Csak gyorsan látnod kell, hogyan olvassa a fájlt a rendszer.
Nyisd meg a CSV-validátort, ha közvetlen eszközre van szükséged, használd a Gyakran ismételt kérdéseket az általános workflow-részletekhez, térj vissza a CSV-fájlok validálása sikertelen importálás előtt útmutatóhoz a szélesebb ellenőrzőlistáért, és tartsd kéznél a Miért nem érhető el a TOML-kimenet egyes JSON vagy YAML bemeneteknél cikket, amikor a handoff-probléma sorokról konfigurációs adatra vált.